Latest Posts

Data Privacy

Data Management
Distributed Systems
Random Educational Post

Introduction
Machine learning (ML) systems have become increasingly complex over the years, and as a result, their execution strategies have evolved to meet the demands of modern machine learning workflows. In this blog post, we will explore three common ML system execution strategies: data parallel execution, task parallel execution, and parameter servers.
Data Parallel Execution
Data parallel execution is a common execution strategy for training deep neural networks. In data parallel execution, the training data is partitioned across multiple processing units, such as GPUs or CPUs, and each processing unit trains a copy of the model on its own subset of the data. The results from each processing unit are then combined to update the model parameters. This approach allows for the efficient processing of large datasets and can scale well to large clusters.
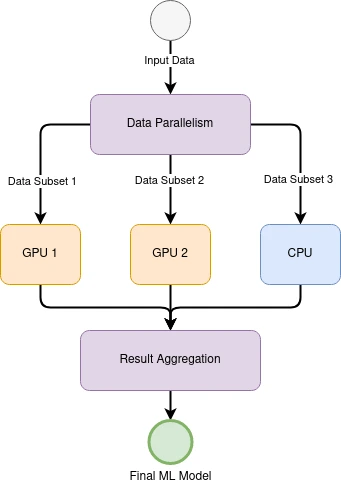
One challenge with data parallel execution is that it requires significant communication between processing units. As each processing unit trains its own copy of the model, the results need to be combined periodically to update the model parameters. This communication can become a bottleneck as the number of processing units grows, and can significantly impact training performance.
Task Parallel Execution
Task parallel execution is an execution strategy that focuses on parallelizing the execution of individual tasks within the machine learning workflow. For example, in a data preprocessing pipeline, task parallelism can be used to parallelize the processing of individual data points. This approach can improve the efficiency of the data preprocessing pipeline and reduce overall training time.
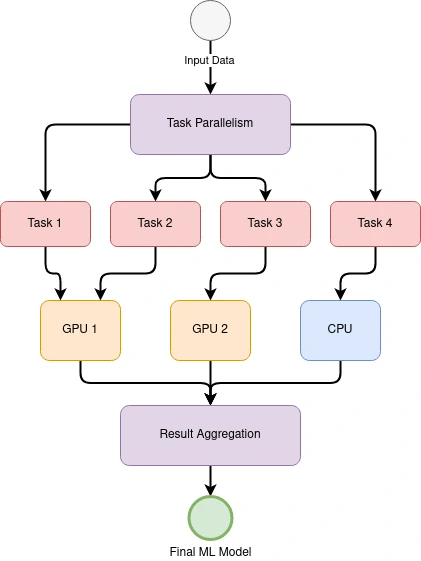
In task parallel execution, individual tasks are assigned to processing units based on availability. As each task completes, the processing unit is assigned a new task to work on. This approach can be used in conjunction with data parallelism to achieve high levels of parallelism and improve overall training performance.
Parameter Servers
Parameter servers are a common execution strategy for distributed machine learning systems. In this approach, the model parameters are stored on a centralized server, while the processing units handle the computation of model updates. Each processing unit receives a subset of the training data and computes the updates to the model parameters based on its own subset of the data. The updates are then sent to the parameter server, which combines the updates and updates the model parameters.
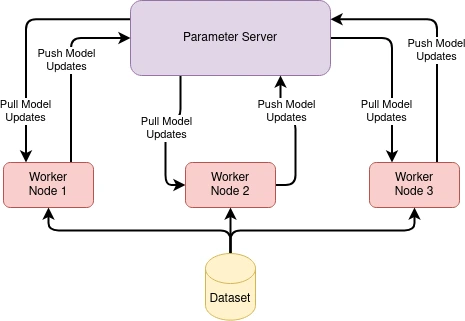
Parameter servers can be used in conjunction with data parallelism to achieve high levels of parallelism and improve training performance. This approach allows for efficient communication between processing units, as the updates are sent to a centralized server for processing. However, parameter servers can become a bottleneck as the number of processing units grows, and can significantly impact training performance.
Conclusion
Machine learning systems have evolved to meet the demands of modern machine learning workflows. Data parallel execution, task parallel execution, and parameter servers are three common execution strategies used in distributed machine learning systems. Each strategy has its own strengths and weaknesses, and the choice of strategy depends on the specific needs of the machine learning workflow. By understanding the different execution strategies available, machine learning practitioners can design efficient and scalable machine learning systems.
Subscribe to our newsletter
And keep up with the infosec industry :)